- Что такое Hadoop и как он работает?
- Основные принципы Hadoop
- Архитектура Hadoop
- Функции Hadoop
- Преимущества использования Hadoop
- Где применяется Hadoop?
- Установка и настройка Hadoop
- Выбор версии Hadoop
- Требования к системе для установки Hadoop
- Установка Hadoop на локальной машине
- Настройка Hadoop для работы с данными
- Вопрос-ответ:
- Что такое Hadoop?
- Какие основные принципы лежат в основе Hadoop?
- Какие функции выполняет Hadoop?
- Какие преимущества предоставляет Hadoop?
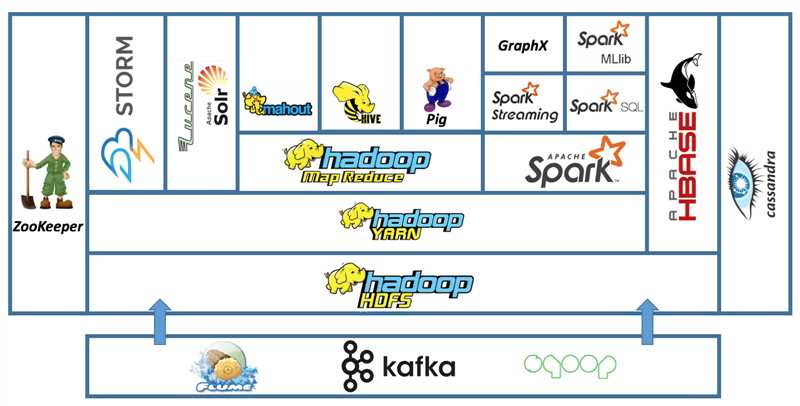
- Какие компоненты входят в Hadoop?
- Что такое Hadoop и для чего он используется?

Hadoop – это мощная и распределенная система для обработки и хранения больших данных.
Основным принципом Hadoop является разделение данных и вычислений, что позволяет эффективно обрабатывать и анализировать огромные объемы информации. Архитектура Hadoop основывается на принципе «распределенной файловой системы» (HDFS) и фреймворке для выполнения вычислений (MapReduce).
Hadoop обеспечивает масштабируемость, надежность и отказоустойчивость, благодаря чему является оптимальным решением для обработки больших данных. Он используется во множестве предметных областей, включая поисковые движки, анализ данных, машинное обучение и многое другое.
Основными функциями Hadoop являются:
- Распределенное хранение данных с помощью HDFS.
- Выполнение параллельных вычислений с использованием MapReduce.
- Управление кластером с помощью специальных инструментов и интерфейсов.
Преимуществами Hadoop являются:
- Способность обрабатывать и обрабатывать большие объемы данных.
- Масштабируемость, позволяющая расширять вычислительные ресурсы.
- Надежность, обеспечивающая отказоустойчивость и сохранность данных.
- Открытый и гибкий код, что позволяет настраивать систему под свои нужды и дополнять ее новыми функциями.
Что такое Hadoop и как он работает?
Hadoop основан на концепции распределенного хранения и обработки данных, которая позволяет использовать кластер из множества компьютеров для эффективного выполнения задач. Компьютеры в кластере могут быть несколько различными и необходимо специальное программное обеспечение, чтобы объединить их вместе и управлять ими.
Одной из главных особенностей Hadoop является его файловая система Hadoop Distributed File System (HDFS), которая разбивает данные на блоки и распределяет их по разным узлам в кластере. Это обеспечивает отказоустойчивость и высокую производительность при обработке данных.
В Hadoop используется модель вычислений MapReduce, которая разделяет задачу на два шага: сначала выполняется функция map, которая обрабатывает каждый блок данных независимо, а затем — функция reduce, которая объединяет результаты от разных узлов.
Одним из ключевых преимуществ Hadoop является возможность обработки больших объемов данных, которые не могут быть обработаны на одиночном сервере. Hadoop позволяет работать с данными, размещенными на разных узлах кластера, обеспечивая высокую отказоустойчивость и скорость обработки.
В заключение, Hadoop является мощным инструментом для обработки больших данных, который позволяет эффективно использовать распределенные вычисления. Он позволяет работать с большими объемами данных и обеспечивает отказоустойчивость и высокую производительность обработки данных.
Основные принципы Hadoop
Параллельное распределение данных и обработки — одна из основных принципов Hadoop. Вместо того чтобы обрабатывать данные на одном компьютере, Hadoop разделяет данные и задачи на множество компьютеров, выполняя их параллельно. Это позволяет ускорить обработку данных и справиться с большими объемами информации.
Файловая система Hadoop (HDFS) — это еще один важный принцип фреймворка. HDFS использует распределенное хранение данных на кластере компьютеров. Данные разделяются на блоки и реплицируются на разных узлах кластера, что обеспечивает отказоустойчивость и доступность данных.
Модель программирования MapReduce — еще одна ключевая составляющая Hadoop. MapReduce — это способ обработки данных, в котором задачи разделяются на две фазы: фазу отображения (Map) и фазу свертки (Reduce). Фаза отображения выполняется параллельно на разных узлах кластера, а результаты сворачиваются в единый результат.
Расширяемость и гибкость — также являются важными принципами Hadoop. Hadoop позволяет легко масштабировать кластер, добавлять новые узлы для обработки данных. Кроме того, фреймворк поддерживает различные языки программирования, что позволяет разработчикам использовать свои предпочтительные инструменты и технологии.
Соблюдение этих принципов позволяет Hadoop обеспечивать высокую производительность, отказоустойчивость и гибкость при обработке и анализе больших объемов данных.
Архитектура Hadoop
Основными компонентами архитектуры Hadoop являются:
| Компонент | Описание |
|---|---|
| Hadoop Distributed File System (HDFS) | Это распределенная файловая система, разработанная специально для хранения и обработки больших данных. Она разбивает данные на блоки и дублирует их на различных узлах кластера, обеспечивая надежность и отказоустойчивость. |
| Hadoop MapReduce | Это модель программирования и исполнения, предназначенная для обработки данных в распределенной среде. Она позволяет разделить задачу на несколько подзадач, выполняемых параллельно на узлах кластера, а затем объединить результаты вычислений. |
| Hadoop YARN | Это архитектурный фреймворк, отвечающий за управление ресурсами и планирование задач в кластере Hadoop. Он позволяет эффективно распределять ресурсы между различными задачами и приложениями. |
Архитектура Hadoop обеспечивает масштабируемость и отказоустойчивость, позволяя обрабатывать большие объемы данных на кластере из сотен и тысяч узлов. Она также предлагает простой интерфейс для программирования и управления данными, что делает ее популярным выбором для решения задач Big Data.
Функции Hadoop
| Хранение данных | Hadoop использует Hadoop Distributed File System (HDFS), который предоставляет распределенное хранение данных на нескольких узлах. Это позволяет обрабатывать информацию большого объема и повышает отказоустойчивость. |
| Обработка данных | Hadoop осуществляет обработку больших данных, распределяя задачи на кластере компьютеров. Он позволяет параллельно выполнять задачи обработки и анализировать данные в реальном времени. |
| Масштабируемость | Hadoop обеспечивает горизонтальную масштабируемость, что означает, что при необходимости можно добавить новые узлы к кластеру, чтобы обработать больше данных. Это позволяет расширять мощности хранения и обработки данных без простоев системы. |
| Отказоустойчивость | Благодаря распределенному хранению данных и дублированию, Hadoop обеспечивает отказоустойчивость. Если один узел выходит из строя, данные автоматически реплицируются на другие узлы и задачи переназначаются. |
| Обработка различных типов данных | Hadoop поддерживает обработку различных типов данных, включая структурированные, полуструктурированные и неструктурированные данные. Это позволяет анализировать данные разной природы, включая текстовые, аудио-, видеофайлы и другие. |
Функции Hadoop позволяют эффективно обрабатывать большие объемы данных, а также использовать их для получения ценной информации и принятия эффективных решений.
Преимущества использования Hadoop
Существует несколько веских преимуществ, которые делают Hadoop незаменимым инструментом для обработки и анализа больших данных:
- Масштабируемость: Hadoop позволяет обрабатывать огромные объемы данных, распределяя их между несколькими узлами в кластере. Такая архитектура позволяет горизонтально масштабировать систему, добавляя новые узлы при необходимости, и обеспечивает высокую производительность.
- Отказоустойчивость: Hadoop обладает встроенной отказоустойчивостью благодаря своей архитектуре. Если один из узлов в кластере выходит из строя, задачи автоматически переносятся на другие доступные узлы, что позволяет минимизировать негативные последствия сбоев и обеспечивает непрерывность работы системы.
- Гибкость и универсальность: Hadoop поддерживает обработку различных типов данных и предоставляет возможность использовать различные модули для обработки, хранения и анализа данных. Hadoop экосистема включает в себя такие инструменты, как HDFS (Hadoop Distributed File System), MapReduce, Hive, Pig, Spark и многие другие, что позволяет адаптировать систему под различные требования и задачи.
- Экономическая целесообразность: Hadoop представляет собой открытое программное обеспечение и может быть развернут на доступных и недорогих оборудованиях. Это позволяет существенно снизить затраты на обработку и хранение больших объемов данных по сравнению с традиционными методами. Кроме того, Hadoop позволяет использовать дешевые компьютеры-узлы, что дополнительно сокращает затраты на оборудование.
- Скорость и эффективность: Hadoop обеспечивает высокую скорость обработки данных благодаря распределенной обработке и параллельному выполнению задач. Это позволяет быстро анализировать большие объемы данных и получать результаты в режиме реального времени, что является важным преимуществом для таких областей, как машинное обучение, аналитика больших данных и бизнес-аналитика.
- Открытость и активное сообщество: Hadoop является открытым проектом с активным сообществом разработчиков и пользователей. Это обеспечивает поддержку и развитие системы, а также возможность обмена опытом и свободного доступа к новым инструментам и решениям.
Все эти преимущества делают Hadoop незаменимым инструментом для работы с большими объемами данных и обработки сложных аналитических задач.
Где применяется Hadoop?
- Интернет-поиск: Многие крупные поисковые системы, такие как Google, используют Hadoop для обработки и анализа огромных объемов данных.
- Анализ социальных сетей: Hadoop позволяет анализировать и обрабатывать данные из социальных сетей для выявления тенденций, моделей поведения пользователей и прогнозирования трендов.
- Финансовая аналитика: Банки, страховые компании и другие организации используют Hadoop для анализа финансовых данных, выявления мошенничества, прогнозирования рыночных трендов и оптимизации портфеля активов.
- Медицинские исследования: Hadoop помогает обрабатывать и анализировать медицинские данные, такие как данные о геноме человека, результаты клинических испытаний и электронные медицинские записи, в целях поиска лекарственных препаратов и разработки индивидуального подхода к лечению.
- Интернет вещей: В связи с ростом числа устройств IoT (интернета вещей) возникает необходимость обрабатывать и анализировать большие объемы данных, и Hadoop предоставляет эффективные средства для этого.
- Логистика и транспорт: Hadoop используется для анализа данных о передвижении и грузопотоках, оптимизации маршрутов и прогнозирования спроса.
Это только некоторые области, где Hadoop проявляет себя как незаменимый инструмент. Благодаря своим преимуществам в обработке и хранении больших данных, Hadoop стал основным инструментом для решения сложных задач анализа данных во многих отраслях.
Установка и настройка Hadoop
Перед началом установки и настройки Hadoop необходимо убедиться, что на компьютере установлена Java Development Kit (JDK) версии 8 или выше.
Шаги установки и настройки Hadoop:
- Скачайте архив Hadoop с официального сайта и распакуйте его в желаемый каталог.
- Откройте файл hadoop-env.sh в папке etc/hadoop и найдите переменную JAVA_HOME. Установите ей значение пути к JDK.
- Откройте файл core-site.xml в папке etc/hadoop и укажите следующие настройки:
- fs.defaultFS — установите значение в формате hdfs://localhost:9000, где localhost — имя вашего компьютера.
- hadoop.tmp.dir — установите значение пути к временным файлам Hadoop.
- Откройте файл hdfs-site.xml в папке etc/hadoop и укажите следующие настройки:
- dfs.replication — установите значение количества реплик файлов в системе.
- dfs.namenode.name.dir — установите значение пути к каталогам имени узла Hadoop.
- dfs.datanode.data.dir — установите значение пути к каталогам данным узла Hadoop.
- Откройте файл yarn-site.xml в папке etc/hadoop и укажите следующие настройки:
- yarn.nodemanager.aux-services — установите значение как mapreduce_shuffle.
- yarn.nodemanager.aux-services.mapreduce.shuffle.class — установите значение как org.apache.hadoop.mapred.ShuffleHandler.
- yarn.resourcemanager.hostname — установите значение в формате localhost или IP-адрес вашего компьютера.
- Скопируйте файлы mapred-site.xml.template и capacity-scheduler.xml.template из папки etc/hadoop в эту же папку, переименуйте их в mapred-site.xml и capacity-scheduler.xml соответственно.
- Откройте файл mapred-site.xml и укажите следующие настройки:
- mapred.framework.name — установите значение в mapreduce.
- mapreduce.jobtracker.address — установите значение в localhost:54311.
- mapreduce.jobhistory.address — установите значение в localhost:10020.
- Откройте файл capacity-scheduler.xml и настройте использование ресурсов системы в соответствии с вашими потребностями.
- Сохраните все изменения.
После завершения настройки, Hadoop готов к использованию.
Выбор версии Hadoop
При выборе версии Hadoop необходимо учитывать несколько важных аспектов.
В первую очередь стоит обратить внимание на стабильность и поддержку версии. Компания Apache, которая разрабатывает и поддерживает Hadoop, периодически выпускает новые версии, в которых исправляются обнаруженные ошибки и улучшается функциональность. Это означает, что более новые версии могут предоставлять новые возможности и улучшенную производительность.
Однако, при переходе на новую версию Hadoop необходимо учитывать возможные проблемы совместимости с уже существующими приложениями и инфраструктурой. Некоторые функции или настройки могут измениться, что может потребовать дополнительной работы для обновления и адаптации приложений.
Более старые версии Hadoop также могут быть полезны в случаях, когда существует необходимость в использовании конкретной функциональности, которая была удалена или изменена в более новых версиях. Однако, при использовании старых версий необходимо учитывать возможные уязвимости безопасности и отсутствие последних исправлений ошибок.
В конечном счете, выбор версии Hadoop должен быть обоснован на основе требований проекта, доступных ресурсов и ожидаемых результатов. Рекомендуется оценивать преимущества и недостатки каждой версии и проводить тестирование перед окончательным решением.
Требования к системе для установки Hadoop
Перед установкой Hadoop необходимо убедиться, что ваша система соответствует определенным требованиям. Вот основные требования к системе для успешной установки и работы Hadoop:
1. Операционная система:
Hadoop поддерживает установку на различные операционные системы, включая Linux, Windows и MacOS. Рекомендуется использовать одну из последних версий операционных систем, чтобы гарантировать совместимость и получить наилучшую производительность.
2. Java Development Kit (JDK):
Hadoop разработан на языке Java, поэтому перед установкой необходимо установить Java Development Kit (JDK) версии 1.7 или выше. Убедитесь, что переменная среды JAVA_HOME указывает на установленный JDK.
3. Процессор:
Hadoop является ресурсоемким приложением, поэтому для эффективной работы рекомендуется иметь мощный процессор. Рекомендуется использовать процессор с несколькими ядрами для обеспечения параллельной обработки.
4. Оперативная память (RAM):
Для установки и работы Hadoop рекомендуется иметь достаточный объем оперативной памяти. Объем RAM должен быть не менее 4 ГБ, но лучше использовать 8 ГБ или больше для обеспечения эффективной обработки и хранения данных.
5. Хранилище:
Hadoop предназначен для обработки и хранения больших объемов данных. Требуется наличие достаточного объема дискового пространства для хранения данных. Рекомендуется использовать RAID-массивы или распределенные файловые системы (например, HDFS), чтобы обеспечить отказоустойчивость и масштабируемость хранилища.
6. Сеть:
Hadoop поддерживает распределенную обработку данных, поэтому требуется наличие сетевых соединений между узлами кластера. Убедитесь, что у вас есть стабильная сеть с достаточной пропускной способностью для обмена данными между узлами.
Соблюдение этих требований поможет вам успешно установить и использовать Hadoop на вашей системе.
Установка Hadoop на локальной машине
Для установки Hadoop на локальной машине необходимо выполнить следующие шаги:
- Скачайте архив с Hadoop с официального веб-сайта проекта.
- Распакуйте скачанный архив в директорию, где вы хотите установить Hadoop.
- Настройте переменные окружения, чтобы можно было использовать команды Hadoop из любого места в системе. Добавьте путь к директории, где распакован Hadoop, в переменную PATH.
- Откройте файл конфигурации Hadoop (hadoop-env.sh) и установите путь к JDK, установленному на вашей машине.
- Настройте файлы конфигурации Hadoop (core-site.xml, hdfs-site.xml и т.д.) в соответствии с вашими потребностями. Особое внимание уделите настройке пути к директории, где будет храниться файловая система Hadoop (HDFS).
- Запустите Hadoop, выполните команду start-all.sh из директории, где установлен Hadoop. Это запустит необходимые демоны Hadoop, включая NameNode и DataNode.
После завершения этих шагов Hadoop будет успешно установлен и готов к использованию на вашей локальной машине.
Важно: Помните, что Hadoop — это сложный и мощный инструмент, и его установка и настройка могут потребовать некоторого времени и усилий. Рекомендуется ознакомиться с документацией и руководством по установке Hadoop, чтобы извлечь максимальную пользу из этой технологии.
Настройка Hadoop для работы с данными
Перед началом работы с Hadoop необходимо выполнить несколько настроек для обеспечения эффективной работы с данными.
1. Установить и сконфигурировать Java Development Kit (JDK). Hadoop требует наличия JDK для своей работы. Для установки JDK можно воспользоваться официальным сайтом Oracle, где можно скачать последнюю версию JDK для вашей операционной системы. После установки необходимо настроить переменные среды JAVA_HOME и PATH.
2. Скачать и установить Hadoop. Hadoop можно скачать с официального сайта проекта, где доступны последние версии Hadoop. После скачивания необходимо распаковать архив и перейти в каталог с распакованными файлами.
3. Настроить конфигурационные файлы. Hadoop использует несколько конфигурационных файлов, в которых нужно указать пути к различным ресурсам и настройки для работы кластера. Некоторые из наиболее важных файлов:
| Название файла | Описание |
|---|---|
| hadoop-env.sh | Настройки среды исполнения Hadoop |
| core-site.xml | Настройки Hadoop Core, такие как пути к файловой системе и порты для сервисов |
| hdfs-site.xml | Настройки Hadoop Distributed File System (HDFS) |
| yarn-site.xml | Настройки Yet Another Resource Negotiator (YARN) |
| mapred-site.xml | Настройки MapReduce |
4. Запустить Hadoop в режиме одной ноды для проверки работоспособности. Для этого необходимо выполнить следующую команду: hadoop namenode -format, затем start-all.sh. После успешного запуска можно проверить статус Hadoop командой jps.
5. Настройка Hadoop для работы с данными. После успешного запуска Hadoop можно начать работу с данными. Для этого необходимо создать HDFS с помощью команды hadoop fs -mkdir /mydata. Затем можно копировать данные в HDFS с помощью команды hadoop fs -put /local/file /mydata/.
После выполнения всех вышеуказанных шагов Hadoop будет готов к работе с вашими данными. При необходимости можно настраивать дополнительные параметры и приводить рабочую среду в соответствие с требованиями вашего проекта.
Вопрос-ответ:
Что такое Hadoop?
Hadoop — это открытая платформа, предназначенная для обработки и хранения больших объемов данных. Она состоит из фреймворка для распределенной обработки данных и файловой системы Hadoop Distributed File System (HDFS).
Какие основные принципы лежат в основе Hadoop?
Основные принципы Hadoop — это распределенная обработка данных и обработка данных в памяти, а также автоматическое восстановление отказов. Hadoop разбивает данные на блоки и распределяет их по узлам кластера для параллельной обработки. При возникновении сбоев, данные автоматически реплицируются на другие узлы.
Какие функции выполняет Hadoop?
Hadoop выполняет функции распределенной обработки данных, хранения данных, параллельной обработки и анализа больших данных, а также автоматического распределения и восстановления данных.
Какие преимущества предоставляет Hadoop?
Hadoop предоставляет ряд преимуществ, включая возможность обработки больших объемов данных, распределение работы между несколькими узлами кластера для повышения скорости обработки, автоматическую репликацию данных для обеспечения отказоустойчивости и упрощение процесса анализа данных.
Какие компоненты входят в Hadoop?
Hadoop состоит из нескольких компонентов, включая Hadoop Distributed File System (HDFS), MapReduce, Hadoop YARN и Hadoop Common. HDFS — это распределенная файловая система, MapReduce — это фреймворк для распределенной обработки данных, Hadoop YARN — ресурсный менеджер, а Hadoop Common — набор утилит и библиотек, используемых всеми компонентами Hadoop.
Что такое Hadoop и для чего он используется?
Hadoop — это фреймворк для распределенной обработки и анализа больших объемов данных. Он используется для хранения, обработки и анализа данных, которые не могут быть обработаны на одном компьютере из-за их размера или специфики.