- Что такое Hadoop?
- Принцип работы
- Распределенная файловая система
- Алгоритмы обработки данных
- Масштабируемость и отказоустойчивость
- Области применения
- Анализ больших данных
- Машинное обучение
- Облачные вычисления
- Преимущества и недостатки
- Преимущества Hadoop
- Недостатки Hadoop
- Вопрос-ответ:
- Какая роль у Hadoop в обработке и хранении больших данных?
- Какие основные компоненты входят в состав Hadoop?
- Как работает Hadoop Distributed File System (HDFS)?
- Какая роль у Apache MapReduce в Hadoop?
- Какие преимущества имеет использование Hadoop для обработки больших данных?

Hadoop — это фреймворк для обработки и анализа больших данных. Он был создан сотрудниками компании Yahoo для того, чтобы обеспечить хранение и обработку огромных объемов информации. Hadoop предлагает решение для проблемы обработки данных, которые не помещаются на один компьютер или не могут быть обработаны в разумные временные рамки. Он предоставляет средства для распределения обработки данных на кластере компьютеров, что позволяет эффективно использовать ресурсы и обрабатывать данные параллельно.
Принцип работы Hadoop основывается на двух ключевых компонентах: Hadoop Distributed File System (HDFS) и Hadoop MapReduce.
Hadoop Distributed File System — это распределенная файловая система, которая предоставляет возможность хранить данные на кластере компьютеров. HDFS разбивает файлы на блоки и реплицирует их на разных узлах кластера, обеспечивая отказоустойчивость и высокую доступность данных. Благодаря такой организации хранения данных, Hadoop может обрабатывать и анализировать информацию с большой скоростью, используя множество компьютеров параллельно.
Hadoop MapReduce — это модель программирования, которая позволяет распределенно обрабатывать данные на кластере компьютеров. Она основывается на принципах функционального программирования, где данные разбиваются на небольшие фрагменты и обрабатываются независимо друг от друга на разных узлах кластера. Результаты обработки собираются и объединяются в конечный результат.
Использование Hadoop позволяет обрабатывать и анализировать большие объемы данных, которые ранее были недоступны для обычных систем обработки информации. Благодаря своей открытой архитектуре и богатому экосистему инструментов, Hadoop является одним из самых популярных в мире фреймворков для обработки больших данных.
Что такое Hadoop?
Основные компоненты Hadoop:
Hadoop Distributed File System (HDFS) — распределенная файловая система, предназначенная для хранения и обработки данных. HDFS разбивает данные на блоки и распределяет их по узлам кластера. Это обеспечивает отказоустойчивость и возможность обработки данных параллельно.
MapReduce — программная модель, используемая для обработки данных в Hadoop. Она позволяет разбить задачу на несколько независимых подзадач и выполнять их параллельно на разных узлах кластера. MapReduce обеспечивает абстракцию для работы с данными и автоматически обрабатывает детали распределенной обработки данных.
YARN (Yet Another Resource Negotiator) — менеджер ресурсов в Hadoop. YARN обеспечивает распределение ресурсов кластера (процессорное время, память, диск) между приложениями, работающими на Hadoop. Он позволяет эффективно использовать ресурсы и обрабатывать данные в реальном времени.
Hadoop Common — набор утилит и библиотек, общих для всех компонентов Hadoop. Он включает в себя инструменты для работы с файлами, сетью, безопасностью и другими аспектами системы.
Благодаря своей открытой природе и гибкости, Hadoop широко используется в различных областях, включая аналитику данных, обработку логов, машинное обучение и многое другое. Он позволяет эффективно работать с большим объемом структурированных и неструктурированных данных и предоставляет средства для их обработки, хранения и анализа.
Таким образом, Hadoop является мощной и гибкой платформой для работы с большими объемами данных. Он позволяет организовать эффективную обработку данных в распределенной среде и использовать их для получения ценных знаний и информации.
Принцип работы
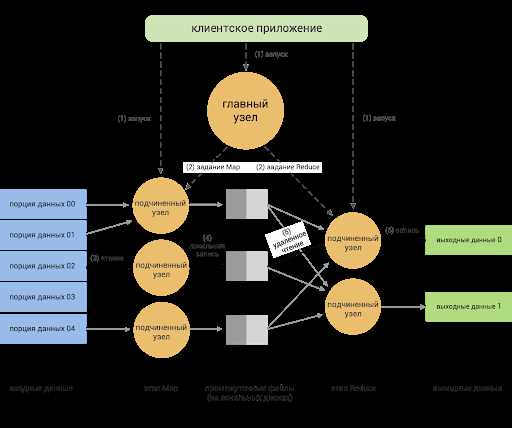
Основными компонентами Hadoop являются Hadoop Distributed File System (HDFS) и Hadoop MapReduce. HDFS разделяет данные на небольшие блоки и распределяет их по узлам кластера, обеспечивая их надежность и доступность. Hadoop MapReduce предоставляет средства для распределенной обработки данных, разбивая задачи на подзадачи и распределяя их по узлам кластера.
Процесс обработки данных в Hadoop состоит из нескольких этапов. Сначала данные разделяются на блоки определенного размера и распределяются по узлам кластера. Затем MapReduce задачи разделяются на два этапа: Map и Reduce. На этапе Map каждый узел кластера обрабатывает один или несколько блоков данных, применяя функцию Map к каждой записи и генерируя набор промежуточных результатов. На этапе Reduce промежуточные результаты объединяются и обрабатываются с помощью функции Reduce, чтобы получить итоговый результат обработки данных.
Одной из особенностей Hadoop является то, что он позволяет выполнять обработку данных на месте, то есть данные обрабатываются в том же месте, где они хранятся, без необходимости перемещать их на централизованное хранилище.
Благодаря своей архитектуре и принципу работы, Hadoop может эффективно обрабатывать огромные объемы данных, обеспечивать отказоустойчивость и открытость для различных типов данных и инструментов анализа. Hadoop также является расширяемым фреймворком, позволяющим добавлять новые компоненты и инструменты, чтобы удовлетворить конкретные потребности анализа данных.
Распределенная файловая система
Распределенная файловая система Hadoop обеспечивает надежность и отказоустойчивость путем репликации (дублирования) данных на различных узлах кластера. Данные разбиваются на блоки фиксированного размера и распределяются по разным узлам кластера. Каждый блок реплицируется на несколько узлов, чтобы обеспечить доступ к данным в случае отказа какого-либо узла.
HDFS предоставляет высокую пропускную способность, так как данные могут читаться и записываться параллельно на нескольких узлах кластера. Для обеспечения отказоустойчивости и высокой производительности, HDFS имеет множество функций, таких как самоисправление ошибок и автоматическое перемещение блоков данных на более доступные узлы.
Распределенная файловая система Hadoop — это не просто обычная файловая система, она предоставляет удивительную способность работать с данными объемом в несколько терабайт и позволяет надежно хранить и обрабатывать данные на больших кластерах серверов.
Алгоритмы обработки данных
В Hadoop используются различные алгоритмы обработки данных для выполнения задач параллельной обработки больших объемов информации. Ниже приведены некоторые из основных алгоритмов, используемых в Hadoop:
| Алгоритм | Описание |
|---|---|
| MapReduce | Алгоритм, основанный на параллельном выполнении задач на узлах кластера. Он разделяет задачу на две части: Map (отображение) и Reduce (сокращение), где Map выполняется независимо на разных узлах, а затем результаты объединяются Reduce. |
| Hadoop Distributed File System (HDFS) | Алгоритм для распределенного хранения и обработки данных. HDFS разделен на блоки, которые реплицируются на различных узлах кластера, обеспечивая отказоустойчивость и высокую скорость доступа к данным. |
| YARN (Yet Another Resource Negotiator) | Алгоритм для управления ресурсами кластера и планирования выполнения задач. YARN разделяет кластер на независимые контейнеры, в которых выполняются задачи, и управляет распределением ресурсов между задачами. |
| Spark | Алгоритм для обработки данных в памяти, который позволяет выполнять операции с данными непосредственно в памяти, что дает высокую скорость обработки. Spark может интегрироваться с Hadoop и использовать его функциональность. |
| Hive | Алгоритм для выполнения SQL-запросов на данных, хранящихся в Hadoop. Hive предоставляет аналогичный SQL-интерфейс к данным, что упрощает работу с большими объемами информации. |
Это лишь несколько примеров алгоритмов, используемых в Hadoop. Платформа предоставляет гибкое окружение для разработки и реализации различных алгоритмов обработки данных, позволяя анализировать, обрабатывать и извлекать ценную информацию из больших объемов данных.
Масштабируемость и отказоустойчивость
Благодаря своей архитектуре, Hadoop обеспечивает отказоустойчивость данных. По умолчанию, каждый блок данных в HDFS реплицируется на несколько узлов кластера. Это позволяет сохранить данные в случае отказа одного или нескольких узлов. При возникновении сбоя, Hadoop автоматически использует реплики для продолжения работы и восстанавливает потерянные копии данных.
Более того, Hadoop спроектирован таким образом, чтобы обеспечить масштабируемость и отказоустойчивость на больших расстояниях. Кластеры Hadoop могут быть развернуты в разных географических областях, и данные могут быть реплицированы между ними. Это позволяет обеспечить доступность данных, даже в случае полного отказа одной из областей.
Области применения
- Анализ данных: Hadoop позволяет проводить масштабные и сложные анализы данных, включая обработку неструктурированных данных. Он позволяет обрабатывать огромные объемы данных и извлекать полезную информацию для принятия правильных решений.
- Обработка и хранение данных: Hadoop предоставляет распределенное хранение и обработку данных, что позволяет эффективно работать с большими объемами информации без необходимости использования дорогостоящего оборудования и специализированного программного обеспечения.
- Интернет вещей (IoT): Hadoop может использоваться для обработки и анализа данных, собираемых с устройств Интернета вещей. Он обеспечивает масштабируемость и надежность в обработке данных с большого количества устройств, что помогает сделать выводы и принять решения на основе этих данных.
- Машинное обучение и искусственный интеллект: Hadoop предоставляет возможности для обучения моделей машинного обучения и использования их для прогнозирования и принятия решений. С его помощью можно обрабатывать и анализировать большие объемы данных, необходимые для обучения моделей искусственного интеллекта.
- Рекомендательные системы: Hadoop может быть использован для создания рекомендательных систем, которые анализируют поведение пользователей и предлагают им релевантные рекомендации. Это полезно для маркетинга и повышения удовлетворенности пользователей.
- Безопасность данных: Hadoop обеспечивает надежную защиту данных и доступ только авторизованным пользователям. Он предоставляет средства для шифрования данных и контроля доступа, что является важным в условиях увеличения угроз информационной безопасности.
Это лишь некоторые области применения Hadoop. С его помощью можно проводить различные типы анализа данных и решать разнообразные задачи в области обработки и хранения информации.
Анализ больших данных
Одним из инструментов, предназначенных для решения задач анализа больших данных, является Hadoop. Hadoop — это открытая платформа, которая предоставляет средства для распределенного хранения и обработки данных. Hadoop основывается на концепции распределенного файлового хранилища HDFS (Hadoop Distributed File System) и параллельного выполнения задач на кластере компьютеров.
Hadoop позволяет эффективно обрабатывать данные различных форматов: структурированные, полуструктурированные и неструктурированные. Этот инструмент также предоставляет широкий набор функциональных возможностей для анализа данных, включая распределенные операции сортировки, агрегации, фильтрации, группировки и другие.
Благодаря своей архитектуре и возможностям, Hadoop обеспечивает высокую отказоустойчивость и масштабируемость при работе с большими данными. Hadoop позволяет проводить аналитику на огромных объемах информации, что позволяет организациям принимать обоснованные решения на основе данных и получать ценные практические результаты.
Необходимо отметить, что Hadoop является лишь одним из инструментов для анализа больших данных. Существуют и другие платформы и технологии, такие как Apache Spark, Apache Flink, HBase, которые также предоставляют средства для работы с большими данными и имеют свои преимущества и особенности.
В итоге, анализ больших данных с помощью Hadoop и других инструментов становится все более популярным в современном мире и позволяет организациям извлекать ценные знания и информацию из огромных объемов данных, что способствует развитию бизнеса и принятию обоснованных решений.
Машинное обучение
Машинное обучение может быть использовано для решения широкого круга задач, включая классификацию данных, прогнозирование, кластеризацию, распознавание образов, обработку естественного языка и многое другое. Оно широко применяется в различных отраслях, включая медицину, финансы, транспорт, рекламу и многие другие.
Машинное обучение основано на использовании больших объемов данных и способности компьютеров обрабатывать и анализировать их быстро. Hadoop является мощным инструментом для обработки и анализа больших данных, что позволяет эффективно применять методы машинного обучения к реальным задачам.
Преимущества машинного обучения включают автоматизацию процессов, повышение точности прогнозирования, оптимизацию ресурсов и уменьшение рисков ошибок. Благодаря постоянному обучению и адаптации, алгоритмы машинного обучения могут стать все более эффективными с течением времени.
Облачные вычисления

Облачные вычисления могут быть организованы по-разному, включая публичные, частные и гибридные облака. Публичные облака предоставляют ресурсы для любого пользователя, который платит за их использование. Частные облака нацелены на ограниченную аудиторию и используются организациями, которым требуется большой уровень контроля над данными и безопасностью. Гибридные облака сочетают в себе элементы публичных и частных облаков и позволяют организациям настраивать баланс между уровнем контроля и гибкостью использования.
Облачные вычисления предлагают множество преимуществ для бизнеса и частных пользователей. Во-первых, облачные ресурсы могут быть легко масштабированы в зависимости от потребностей. Если у вас возникает нужда в большей вычислительной мощности или пространстве для хранения данных, вы можете легко расширить свои ресурсы без необходимости приобретения и обслуживания нового оборудования. Во-вторых, использование облачных вычислений позволяет снизить затраты на IT-инфраструктуру, так как вы платите только за использованные ресурсы, а не за всю инфраструктуру целиком. В-третьих, облачные вычисления обеспечивают высокую доступность и надежность, так как провайдеры облака обычно имеют многоцентровую архитектуру, что позволяет переключаться между различными центрами обработки данных в случае возникновения сбоев.
Использование облачных вычислений становится все более популярным среди компаний всех размеров и отраслей, поскольку они позволяют сосредоточиться на основной деятельности, а не на обслуживании и поддержке IT-инфраструктуры. Благодаря облачным вычислениям компании могут быстро масштабировать свои проекты, ускорять развертывание новых приложений и снижать риски, связанные с потерей данных или сбоями системы.
Преимущества и недостатки
Преимущества Hadoop:
- Масштабируемость: Hadoop позволяет масштабировать хранение и обработку данных горизонтально, добавляя дополнительные узлы.
- Отказоустойчивость: благодаря репликации данных и дублированию задач, Hadoop обеспечивает высокую отказоустойчивость.
- Распределенная обработка данных: Hadoop распределяет обработку данных по кластеру узлов, что позволяет справляться с большими объемами данных более эффективно.
- Экономическая выгода: Hadoop использует недорогие оборудование с открытым исходным кодом, что значительно снижает затраты на хранение и обработку данных.
- Поддержка различных типов данных: Hadoop способен обрабатывать различные типы данных, включая структурированные и неструктурированные данные.
Недостатки Hadoop:
- Сложность использования: Hadoop является сложной технологией, требующей глубоких знаний и опыта для настройки и управления.
- Высокие требования к аппаратному обеспечению: для эффективной работы Hadoop необходимо обеспечить высокопроизводительные серверы и сети.
- Низкая скорость обработки данных: Hadoop хорошо справляется с большими объемами данных, но обработка данных может занимать больше времени по сравнению с другими технологиями.
- Опасность потери данных: в случае отказа нескольких узлов, возможна потеря данных, если они не были реплицированы.
- Ограничения по типам операций: Hadoop предназначен главным образом для пакетной обработки данных и не слишком эффективен при работе с интерактивными операциями.
Преимущества Hadoop
Масштабируемость: Hadoop позволяет обрабатывать и хранить огромные объемы данных. Он может работать с данными, которые не вмещаются на одном сервере, и распределить их на кластер узлов.
Отказоустойчивость: Hadoop способен автоматически восстанавливаться после сбоев и обеспечивать надежность и доступность данных.
Экономическая эффективность: Hadoop предоставляет возможность использовать несколько недорогих серверов вместо одного дорогостоящего. Это позволяет снизить затраты на оборудование и эксплуатацию.
Гибкость: Hadoop является гибким и масштабируемым фреймворком, который позволяет выполнять различные задачи обработки данных, включая хранение, обработку и анализ.
Высокая скорость обработки: Hadoop обеспечивает высокую скорость обработки данных путем параллельного выполнения задач на разных узлах кластера.
Простота использования: Hadoop предоставляет простой и понятный интерфейс для разработки и выполнения задач обработки данных без необходимости знания сложных алгоритмов и языков программирования.
Однако, несмотря на свои преимущества, Hadoop также имеет некоторые ограничения и сложности использования, которые требуют специальных знаний и опыта для эффективного использования и настройки этого фреймворка.
Недостатки Hadoop
1. Сложность настройки и управления
Hadoop требует опыта и специальных навыков для правильной настройки и управления. Необходимо иметь глубокое понимание архитектуры и компонентов Hadoop, что может создавать трудности для новичков.
2. Ограничения производительности
Hadoop, несмотря на свою масштабируемость, может иметь проблемы с производительностью в случае обработки маленьких файлов или при выполнении операций, требующих частых чтений и записей. При планировании и настройке Hadoop-кластера необходимо учитывать этот факт и принять соответствующие меры для оптимизации производительности.
3. Сложность разработки и отладки
Разработка и отладка приложений для Hadoop может быть сложной и требует дополнительного времени и усилий. Необходимо изучить Hadoop API и использовать MapReduce или другие фреймворки для разработки приложений.
4. Недостаточная безопасность
Hadoop не обеспечивает полную безопасность данных и аутентификацию. Это может быть проблематично для предприятий, работающих с конфиденциальными данными. При развертывании Hadoop-кластера необходимо принять меры для защиты данных.
5. Ограниченная поддержка типов данных
Hadoop лучше всего подходит для обработки структурированных и полуструктурированных данных, таких как логи, текстовые файлы и табличные данные. Однако он может столкнуться с проблемами при работе с нереляционными данными или данными большого объема.
6. Отсутствие реального времени
Hadoop предназначен для обработки и анализа больших объемов данных в пакетном режиме. Это ограничивает его применение в приложениях, требующих реального времени, таких как финансовые торговые системы или системы обработки транзакций.
В целом, Hadoop является мощным инструментом для обработки и анализа больших данных, но его реализация может столкнуться с определенными ограничениями и сложностями.
Вопрос-ответ:
Какая роль у Hadoop в обработке и хранении больших данных?
Hadoop представляет собой фреймворк для обработки и хранения больших данных. Он использует распределенное хранение и параллельную обработку данных на кластере из нескольких узлов, что позволяет выполнять задачи быстрее и эффективнее.
Какие основные компоненты входят в состав Hadoop?
Основные компоненты Hadoop включают в себя Hadoop Distributed File System (HDFS) для хранения данных и Apache MapReduce для параллельной обработки данных. Кроме того, Hadoop включает также другие инструменты, такие как YARN для управления ресурсами и Hadoop Common для общей функциональности.
Как работает Hadoop Distributed File System (HDFS)?
HDFS разбивает данные на блоки, которые затем распределяются по разным узлам кластера для хранения. Данные реплицируются на несколько узлов для обеспечения отказоустойчивости. Когда данные требуются для обработки, они загружаются в оперативную память для параллельной обработки.
Какая роль у Apache MapReduce в Hadoop?
Apache MapReduce является моделью программирования и методом обработки данных в Hadoop. Он делит задачи обработки данных на несколько шагов: сначала выполняется шаг «map», который обрабатывает данные и генерирует промежуточные результаты, затем выполняется шаг «reduce», который объединяет промежуточные результаты и формирует конечные результаты.
Какие преимущества имеет использование Hadoop для обработки больших данных?
Использование Hadoop позволяет обрабатывать большие объемы данных просто и эффективно. Он распределяет обработку данных на несколько узлов, что позволяет выполнять задачи быстрее. Кроме того, Hadoop обеспечивает отказоустойчивость и масштабируемость, благодаря своей архитектуре с использованием кластера из нескольких узлов.